Generate single-cell images 
 ¶
¶
Here, we are going to process the previously ingested microscopy images with the scPortrait pipeline to generate single-cell images that we can use to assess autophagosome formation at a single-cell level.
import lamindb as ln
from collections.abc import Iterable
from pathlib import Path
from scportrait.pipeline.extraction import HDF5CellExtraction
from scportrait.pipeline.project import Project
from scportrait.pipeline.segmentation.workflows import CytosolSegmentationCellpose
ln.track()
Show code cell output
→ connected lamindb: testuser1/test-sc-imaging
→ created Transform('BS6hWDeKg5uw0000', key='sc-imaging2.ipynb'), started new Run('cnYPVyidJvdKMQvR') at 2026-07-12 19:19:47 UTC
→ notebook imports: lamindb-core==2.7.0 scportrait==1.8.0
• tip: to identify the notebook across renames, pass the uid: ln.track("BS6hWDeKg5uw")
Query microscopy images¶
First, we query for the raw and annotated microscopy images.
input_images = ln.Artifact.filter(
ulabels__name="autophagy imaging", description__icontains="raw image", suffix=".tif"
)
The experiment includes two genotypes (WT and EI24KO) under two treatment conditions (unstimulated vs. 14h Torin-1).
Multiple clonal cell lines were imaged for each condition across several fields of view (FOVs) and imaging channels.
We’ll extract single-cell images from each FOV and annotate them with metadata including genotype, treatment condition, clonal cell line, and imaging experiment.
input_images_df = input_images.to_dataframe(features=True)
display(input_images_df.head())
conditions = input_images_df["stimulation"].unique().tolist()
cell_line_clones = input_images_df["cell_line_clone"].unique().tolist()
FOVs = input_images_df["FOV"].unique().tolist()
Show code cell output
! truncated query result to limit=20 Artifact objects
/tmp/ipykernel_3303/1645869880.py:1: DeprecationWarning: `features=True` is deprecated, pass `include="features"` instead.
input_images_df = input_images.to_dataframe(features=True)
| uid | key | genotype | stimulation | cell_line_clone | channel | FOV | magnification | microscope | imaged structure | resolution | study | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||
| 49 | AVRTVX9gEu4LrTAP0000 | input_data_imaging_usecase/images/Timepoint001... | EI24KO | untreated | U2OS lcklip-mNeon mCherryLC3B EI24 KO clone 2 | mCherry | FOV2 | 20X | Opera Phenix | mCherry-LC3B | 0.597976 | autophagy imaging |
| 48 | 6uUjyphUD4D1Hixc0000 | input_data_imaging_usecase/images/Timepoint001... | EI24KO | untreated | U2OS lcklip-mNeon mCherryLC3B EI24 KO clone 2 | mCherry | FOV1 | 20X | Opera Phenix | mCherry-LC3B | 0.597976 | autophagy imaging |
| 47 | AhBvnNKg5yJcG6LU0000 | input_data_imaging_usecase/images/Timepoint001... | EI24KO | untreated | U2OS lcklip-mNeon mCherryLC3B EI24 KO clone 2 | DAPI | FOV2 | 20X | Opera Phenix | DNA | 0.597976 | autophagy imaging |
| 46 | Cvamog4G3a2XYGM80000 | input_data_imaging_usecase/images/Timepoint001... | EI24KO | untreated | U2OS lcklip-mNeon mCherryLC3B EI24 KO clone 2 | DAPI | FOV1 | 20X | Opera Phenix | DNA | 0.597976 | autophagy imaging |
| 45 | Oww4y0yYuR8pxV9q0000 | input_data_imaging_usecase/images/Timepoint001... | EI24KO | untreated | U2OS lcklip-mNeon mCherryLC3B EI24 KO clone 2 | Alexa488 | FOV2 | 20X | Opera Phenix | LckLip-mNeon | 0.597976 | autophagy imaging |
Alternatively, we can query for the ULabel directly:
conditions = ln.ULabel.filter(
links_artifact__feature__name="stimulation", artifacts__in=input_images
).distinct()
cell_line_clones = ln.ULabel.filter(
links_artifact__feature__name="cell_line_clone", artifacts__in=input_images
).distinct()
FOVs = ln.ULabel.filter(
links_artifact__feature__name="FOV", artifacts__in=input_images
).distinct()
By iterating through conditions, cell lines and FOVs, we should only have 3 images showing a single FOV to enable processing using scPortrait.
# Create artifact type feature and associated label
ln.Feature(name="artifact type", dtype=ln.ULabel).save()
ln.ULabel(name="scportrait config").save()
# Load config file for processing all datasets
config_file_af = ln.Artifact.connect("scportrait/examples").get(
key="input_data_imaging_usecase/config.yml"
)
config_file_af.description = (
"config for scportrait for processing of cells stained for autophagy markers"
)
config_file_af.save()
# Annotate the config file with the metadata relevant to the study
config_file_af.features.add_values(
{"study": "autophagy imaging", "artifact type": "scportrait config"}
)
Show code cell output
→ transferred: Artifact(uid='voi8szTkmKPiahUA0000')
Process images with scPortrait¶
Let’s take a look at the processing of one example FOV.
# Get input images for one example FOV
condition, cellline, FOV = conditions[0], cell_line_clones[0], FOVs[0]
images = (
input_images.filter(ulabels=condition)
.filter(ulabels=cellline)
.filter(ulabels=FOV)
.distinct()
)
# Quick sanity check - all images should share metadata except channel/structure
values_to_ignore = ["channel", "imaged structure"]
features = images.first().features.get_values()
shared_features = {k: v for k, v in features.items() if k not in values_to_ignore}
for image in images:
image_features = image.features.get_values()
filtered_features = {
k: v for k, v in image_features.items() if k not in values_to_ignore
}
assert shared_features == filtered_features
# Get image paths in correct channel order
input_image_paths = [
images.filter(ulabels__name=channel).one().cache()
for channel in ["DAPI", "Alexa488", "mCherry"]
]
# Create output directory and unique project ID
output_directory = "processed_data"
unique_project_id = f"{shared_features['cell_line_clone']}/{shared_features['stimulation']}/{shared_features['FOV']}".replace(
" ", "_"
)
project_location = f"{output_directory}/{unique_project_id}/scportrait_project"
# Create directories
Path(project_location).mkdir(parents=True, exist_ok=True)
# Initialize the scPortrait project
project = Project(
project_location=project_location,
config_path=config_file_af.cache(),
segmentation_f=CytosolSegmentationCellpose,
extraction_f=HDF5CellExtraction,
overwrite=True,
)
# Load images and process
project.load_input_from_tif_files(
input_image_paths, overwrite=True, channel_names=["DAPI", "Alexa488", "mCherry"]
)
project.segment()
project.extract()
Show code cell output
Updating project config file.
/tmp/ipykernel_3303/1211438391.py:12: UserWarning: There is already a directory in the location path
project = Project(
0%| | 0.00/25.3M [00:00<?, ?B/s]
1%| | 320k/25.3M [00:00<00:08, 3.09MB/s]
6%|▌ | 1.41M/25.3M [00:00<00:03, 7.68MB/s]
22%|██▏ | 5.59M/25.3M [00:00<00:00, 22.9MB/s]
73%|███████▎ | 18.4M/25.3M [00:00<00:00, 64.0MB/s]
100%|██████████| 25.3M/25.3M [00:00<00:00, 56.4MB/s]
0%| | 0.00/3.54k [00:00<?, ?B/s]
100%|██████████| 3.54k/3.54k [00:00<00:00, 19.0MB/s]
/opt/hostedtoolcache/Python/3.12.13/x64/lib/python3.12/site-packages/cellpose/dynamics.py:760: UserWarning: Sparse invariant checks are implicitly disabled. Memory errors (e.g. SEGFAULT) will occur when operating on a sparse tensor which violates the invariants, but checks incur performance overhead. To silence this warning, explicitly opt in or out. See `torch.sparse.check_sparse_tensor_invariants.__doc__` for guidance. (Triggered internally at /__w/pytorch/pytorch/aten/src/ATen/Context.cpp:816.)
coo = torch.sparse_coo_tensor(pt, torch.ones(pt.shape[1], device=pt.device, dtype=torch.int),
0%| | 0.00/25.3M [00:00<?, ?B/s]
1%|▏ | 336k/25.3M [00:00<00:07, 3.31MB/s]
6%|▌ | 1.48M/25.3M [00:00<00:03, 8.04MB/s]
26%|██▌ | 6.65M/25.3M [00:00<00:00, 28.4MB/s]
69%|██████▉ | 17.6M/25.3M [00:00<00:00, 61.6MB/s]
100%|██████████| 25.3M/25.3M [00:00<00:00, 59.2MB/s]
0%| | 0.00/3.54k [00:00<?, ?B/s]
100%|██████████| 3.54k/3.54k [00:00<00:00, 14.4MB/s]
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2bc908f770>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2bc891c6e0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b699bbce0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b6897e570>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b6919f3b0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b688a80b0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b6870ecc0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2bc931fc50>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b687096d0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68767d40>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b6875fa10>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68dc1280>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b69b95790>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2bc9059460>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b6891a630>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b692172c0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b69216990>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b692452e0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b69273ce0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68e57560>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b691b6b10>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68c682f0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68d34b00>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b693e0800>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68d75fd0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68dba7e0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68c69910>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68e9d1f0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b691b54f0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68e55e50>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68d43680>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b691f9490>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68d03b90>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68919be0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68d35fd0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2bc97f8d10>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68da9850>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68c5aab0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b69215cd0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68e9f440>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b693e2db0>: None
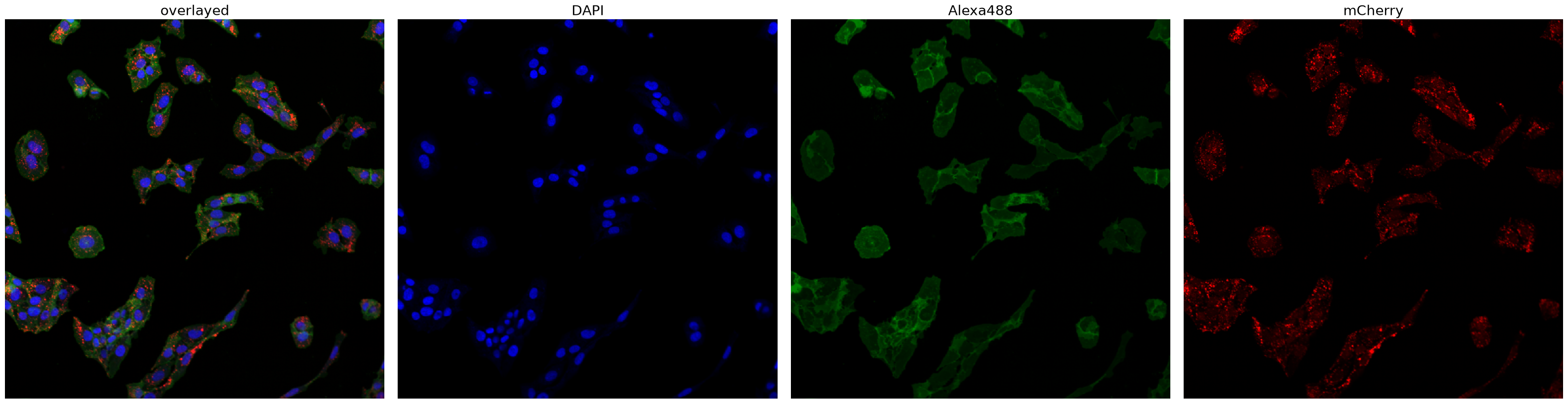
Let’s look at the input images we processed.
project.plot_input_image()
Show code cell output
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68daae70>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b68fc6210>: None
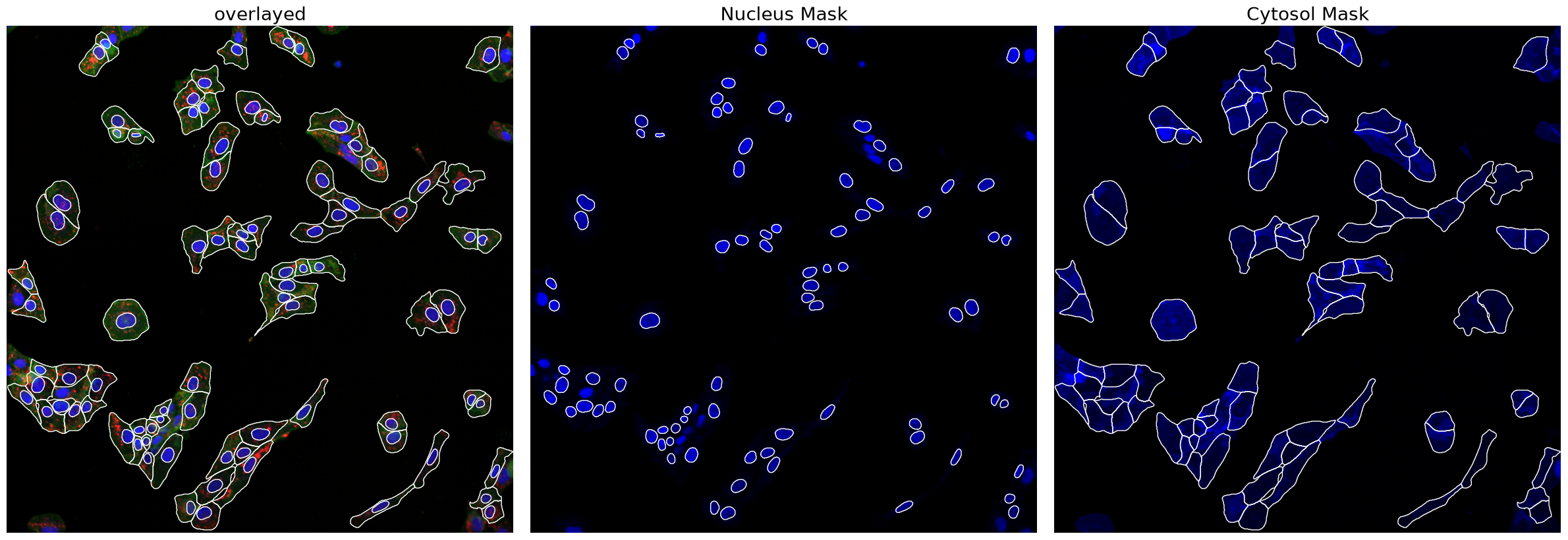
Now we can look at the results generated by scPortrait. First, the segmentation masks.
project.plot_segmentation_masks()
Show code cell output
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b697ba930>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b698fbb00>: None
And then extraction results consisting of individual single-cell images over all of the channels.
project.plot_single_cell_images()
Show code cell output

Save and annotate results¶
Now we also want to save these results to the instance.
ln.Artifact.from_spatialdata(
sdata=project.filehandler.get_sdata(),
description="scportrait spatialdata object containing results of cells stained for autophagy markers",
key=f"processed_data_imaging_use_case/{unique_project_id}/spatialdata.zarr",
).save()
Show code cell output
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2b69a38bc0>: None
WARNING:ome_zarr.reader:no parent found for <ome_zarr.reader.Label object at 0x7f2bc90d5100>: None
Artifact(uid='lnwo02rD9uTGGRSr0000', key='processed_data_imaging_use_case/U2OS_lcklip-mNeon_mCherryLC3B_clone_1/14h_Torin-1/FOV1/spatialdata.zarr', description='scportrait spatialdata object containing results of cells stained for autophagy markers', suffix='.zarr', kind='dataset', otype='SpatialData', size=5806980, hash='fOxQvTiXkoKAUrE9NARA8Q', n_files=67, n_observations=None, extra_data=None, branch_id=1, created_on_id=1, space_id=1, storage_id=1, run_id=3, schema_id=None, created_by_id=1, created_at=2026-07-12 19:21:16 UTC, is_locked=False, version_tag=None, is_latest=True)
# Define schemas for single-cell image dataset
schemas = {
"obs": ln.Schema(
name="single-cell image dataset schema obs",
features=[
ln.Feature(name="scportrait_cell_id", dtype="int", coerce_dtype=True).save()
],
).save(),
"uns": ln.Schema(
name="single-cell image dataset schema uns",
features=[ln.Feature(name="single_cell_images", dtype=dict).save()],
).save(),
}
# Create composite schema
h5sc_schema = ln.Schema(
name="single-cell image dataset",
otype="AnnData",
slots=schemas,
).save()
Show code cell output
! rather than passing a string 'int' to dtype, consider passing a Python object
! you are trying to create a record with name='single-cell image dataset schema uns' but a record with similar name exists: 'single-cell image dataset schema obs'. Did you mean to load it?
! you are trying to create a record with name='single-cell image dataset' but records with similar names exist: 'single-cell image dataset schema obs', 'single-cell image dataset schema uns'. Did you mean to load one of them?
/tmp/ipykernel_3303/1081745476.py:6: DeprecationWarning: `coerce_dtype` argument was renamed to `coerce` and will be removed in a future release.
ln.Feature(name="scportrait_cell_id", dtype="int", coerce_dtype=True).save()
# Curate the AnnData object
curator = ln.curators.AnnDataCurator(project.h5sc, h5sc_schema)
curator.validate()
# Save artifact with annotations
artifact = curator.save_artifact(
key=f"processed_data_imaging_use_case/{unique_project_id}/single_cell_data.h5ad"
)
# Add metadata and labels
annotation = shared_features.copy()
annotation["imaged structure"] = [
ln.ULabel.connect("scportrait/examples").get(name=name)
for name in ["LckLip-mNeon", "DNA", "mCherry-LC3B"]
]
artifact.features.add_values(annotation)
artifact.labels.add(ln.ULabel(name="scportrait single-cell images").save())
Show code cell output
→ returning schema with same hash: Schema(uid='MTy4tozeqm4uqVou', is_type=False, name='single-cell image dataset schema obs', description=None, n_members=1, coerce=None, flexible=False, itype='Feature', otype=None, hash='OL4A2hWLHXh-Srobb12wDQ', minimal_set=True, ordered_set=False, maximal_set=False, branch_id=1, created_on_id=1, space_id=1, created_by_id=1, run_id=3, type_id=None, created_at=2026-07-12 19:21:16 UTC, is_locked=False)
→ returning schema with same hash: Schema(uid='RE5oqCsRzfzzX4OU', is_type=False, name='single-cell image dataset schema uns', description=None, n_members=1, coerce=None, flexible=False, itype='Feature', otype=None, hash='KjXybeiJRsbTZK9gny4oSA', minimal_set=True, ordered_set=False, maximal_set=False, branch_id=1, created_on_id=1, space_id=1, created_by_id=1, run_id=3, type_id=None, created_at=2026-07-12 19:21:16 UTC, is_locked=False)
To process all files in our dataset efficiently, we’ll create a custom image processing function.
We decorate this function with tracked() to track data lineage of the input and output artifacts.
The function will skip files that have already been processed and uploaded, improving processing time by avoiding redundant computations.
@ln.tracked()
def process_images(
config_file_af: ln.Artifact,
input_artifacts: Iterable[ln.Artifact],
h5sc_schema: ln.Schema,
output_directory: str,
) -> None:
# Quick sanity check - all images should share metadata except channel/structure
values_to_ignore = ["channel", "imaged structure"]
first_features = input_artifacts.first().features.get_values()
shared_features = {
k: v for k, v in first_features.items() if k not in values_to_ignore
}
for artifact in input_artifacts:
artifact_features = artifact.features.get_values()
filtered_features = {
k: v for k, v in artifact_features.items() if k not in values_to_ignore
}
assert shared_features == filtered_features
# Create a unique project ID
unique_project_id = f"{shared_features['cell_line_clone']}/{shared_features['stimulation']}/{shared_features['FOV']}".replace(
" ", "_"
)
# Check if already processed
base_key = f"processed_data_imaging_use_case/{unique_project_id}"
try:
ln.Artifact.connect("scportrait/examples").get(
key=f"{base_key}/single_cell_data.h5ad"
)
ln.Artifact.connect("scportrait/examples").get(
key=f"{base_key}/spatialdata.zarr"
)
print("Dataset already processed. Skipping.")
return
except ln.Artifact.DoesNotExist:
pass
# Get image paths in channel order
input_image_paths = [
input_artifacts.filter(ulabels__name=channel).one().cache()
for channel in ["DAPI", "Alexa488", "mCherry"]
]
# Setup and process project
project_location = f"{output_directory}/{unique_project_id}/scportrait_project"
Path(project_location).mkdir(parents=True, exist_ok=True)
project = Project(
project_location=project_location,
config_path=config_file_af.cache(),
segmentation_f=CytosolSegmentationCellpose,
extraction_f=HDF5CellExtraction,
overwrite=True,
)
project.load_input_from_tif_files(
input_image_paths, overwrite=True, channel_names=["DAPI", "Alexa488", "mCherry"]
)
project.segment()
project.extract()
# Save single-cell images
curator = ln.curators.AnnDataCurator(project.h5sc, h5sc_schema)
curator.validate()
artifact = curator.save_artifact(key=f"{base_key}/single_cell_data.h5ad")
annotation = shared_features.copy()
annotation["imaged structure"] = [
ln.ULabel.connect("scportrait/examples").get(name=name)
for name in ["LckLip-mNeon", "DNA", "mCherry-LC3B"]
]
artifact.features.add_values(annotation)
artifact.labels.add(ln.ULabel.get(name="scportrait single-cell images"))
# Save SpatialData object
ln.Artifact.from_spatialdata(
sdata=project.filehandler.get_sdata(),
description="scportrait spatialdata object containing results of cells stained for autophagy markers",
key=f"{base_key}/spatialdata.zarr",
).save()
Show code cell output
/tmp/ipykernel_3303/2251390660.py:1: DeprecationWarning: Use step instead of tracked, tracked will be removed in the future.
@ln.tracked()
Now we are ready to process all of our input images and upload the generated single-cell image datasets back to our instance.
for condition in conditions:
for cellline in cell_line_clones:
for FOV in FOVs:
images = (
input_images.filter(ulabels=condition)
.filter(ulabels=cellline)
.filter(ulabels=FOV)
.distinct()
)
if images:
process_images(
config_file_af,
input_artifacts=images,
h5sc_schema=h5sc_schema,
output_directory=output_directory,
)
Show code cell output
→ ignoring transform with same filename in different folder:
BS6hWDeKg5uw0000 → sc-imaging2.ipynb
→ created Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('6FOn7SshUcyA6wuY', entrypoint='process_images') at 2026-07-12 19:21:17 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[Md4OouMExlWS2YfZ0000]', 'Artifact[CiQYTBNZrj0CPejK0000]', 'Artifact[YGiNq6DPfIEjtt9j0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('A4nUlEd2xcY6VOs0', entrypoint='process_images') at 2026-07-12 19:21:18 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[KKbVRkOjQ1jdA2fx0000]', 'Artifact[W6tzE7JNiM80Ruho0000]', 'Artifact[uuh41FAHEz0ASL2N0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('KbGSWKjjdfAcJBYg', entrypoint='process_images') at 2026-07-12 19:21:19 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[yiIMSAddDWgLgki70000]', 'Artifact[DEzw4QQAsjVZ010b0000]', 'Artifact[hbVyCGFARHU91Kax0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('lyz00EZtxRllYsck', entrypoint='process_images') at 2026-07-12 19:21:19 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[2ie2Kjzn1O7UYhuq0000]', 'Artifact[fOQSb7JCK67aeN6a0000]', 'Artifact[qHQpdWcFu7FzF6l50000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('5Hg4tTOuZ38333t9', entrypoint='process_images') at 2026-07-12 19:21:20 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[jVytS8AyAHmHkYR30000]', 'Artifact[cw4F6bUB9zuMthCY0000]', 'Artifact[7TZGXvbA0JLL68hR0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('kZJ80L7ntPMLqNtP', entrypoint='process_images') at 2026-07-12 19:21:21 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[vCVbKkzz4CnJPPKF0000]', 'Artifact[5kMhlcDNek4RMeQF0000]', 'Artifact[9BmbViqMmlVhpfS00000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('atSzDNYsKRMgIdul', entrypoint='process_images') at 2026-07-12 19:21:21 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[OS0wBE7bviIlW7qj0000]', 'Artifact[ixOpuSTsyrPXdYuA0000]', 'Artifact[6uMjKAk1aYlAV7Cf0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('zFEFB7x3Mw0PAGga', entrypoint='process_images') at 2026-07-12 19:21:22 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[9ZVngbl0JUS0XdZ70000]', 'Artifact[IzP3IAwIhmM7OORD0000]', 'Artifact[RRVS8qVx3VSw02Xu0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('P5zcHgtinCbVSKWj', entrypoint='process_images') at 2026-07-12 19:21:23 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[Gtwi9Pcyx8maQEWB0000]', 'Artifact[sHHpiiFYWsIXMZNV0000]', 'Artifact[hNMkrIHce1XrLZHY0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('vfB8PyC8Ly0vIX9l', entrypoint='process_images') at 2026-07-12 19:21:24 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[nSZhAypqiNZ2Ylbe0000]', 'Artifact[jzqxtoduIJ3hCbB40000]', 'Artifact[M06liaIzh2OVEuJ40000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('a4gcdjeS4XH9hpFZ', entrypoint='process_images') at 2026-07-12 19:21:24 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[mXWwV1x42Jz9RoSO0000]', 'Artifact[gj0HHnoVpEqbaUJb0000]', 'Artifact[1XnEyqVt6UGXCTmV0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('eQOP0t4lBdY9O8BU', entrypoint='process_images') at 2026-07-12 19:21:25 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[Ov8FnKzHMNY0XVJa0000]', 'Artifact[Lwk8shsYe0V5bMgd0000]', 'Artifact[YuyVn060M4FxATPz0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('aPb8BuNssXbICkDU', entrypoint='process_images') at 2026-07-12 19:21:26 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[ThuJnRAhqkp54kyU0000]', 'Artifact[PquYNyshQTDd24Vw0000]', 'Artifact[8SFUmW0RhBNySxBO0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('ZRAJ6d7hFJZagtiM', entrypoint='process_images') at 2026-07-12 19:21:27 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[h4EKWveW36LIzXez0000]', 'Artifact[fdem35nw5ztUnEIM0000]', 'Artifact[VkmKLUCaMsYFCuGE0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('IFB2muSptOeVw6gl', entrypoint='process_images') at 2026-07-12 19:21:27 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[QDPX1ljp0eCMz80o0000]', 'Artifact[Cvamog4G3a2XYGM80000]', 'Artifact[6uUjyphUD4D1Hixc0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
→ loaded Transform('wHT5luVhbZuY0000', key='sc-imaging2.ipynb'), started new Run('wiCxKSg034Duj9uh', entrypoint='process_images') at 2026-07-12 19:21:28 UTC
→ params: config_file_af='Artifact[voi8szTkmKPiahUA0000]', input_artifacts=['Artifact[Oww4y0yYuR8pxV9q0000]', 'Artifact[AhBvnNKg5yJcG6LU0000]', 'Artifact[AVRTVX9gEu4LrTAP0000]'], h5sc_schema='Schema[riBnQ2kagmv0eldX]', output_directory='processed_data'
Dataset already processed. Skipping.
example_artifact = ln.Artifact.filter(
ulabels=ln.ULabel.get(name="scportrait single-cell images")
).first()
example_artifact.view_lineage()
Show code cell output

ln.finish()
Show code cell output
→ finished Run('cnYPVyidJvdKMQvR') after 1m at 2026-07-12 19:21:30 UTC